

金鸣表格文字识别助手
人工智能表格识别准 | 批量合并更便捷
光学字符识别(OCR)技术近年来取得了显著进展,尤其是在文字识别率方面。以金鸣识别为例,肉眼可辨的文字几乎都能被准确识别,甚至对于模糊或低质量的图像,通过引入人工智能(AI)技术,OCR也能“猜测”出正确的字符。然而,OCR技术在实际应用中仍面临一个重要的挑战:如何将识别出的文字转化为结构化数据,尤其是在缺乏明确键名或数据对应关系不明显的情况下。本文将探讨OCR技术的现状、现存困境,并提出通过AI深度学习解决这一问题的可能性。

现代OCR技术结合了传统图像处理方法和深度学习算法,显著提升了识别精度。例如:
以金鸣识别为例,即使是模糊或部分遮挡的文字,AI也能通过上下文和语义分析“猜测”出正确的字符,识别率接近人类水平。
OCR技术不仅需要识别文字,还需要将识别结果转化为结构化数据。例如,在表格识别中,OCR需要将键名(如“姓名”、“年龄”)与键值(如“张三”、“25”)对应起来,形成可用的结构化数据。目前,OCR技术在以下场景中表现良好:
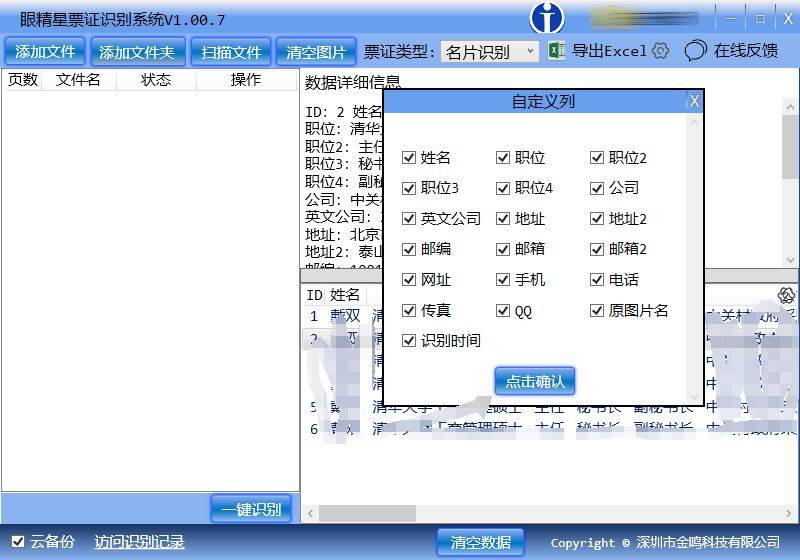
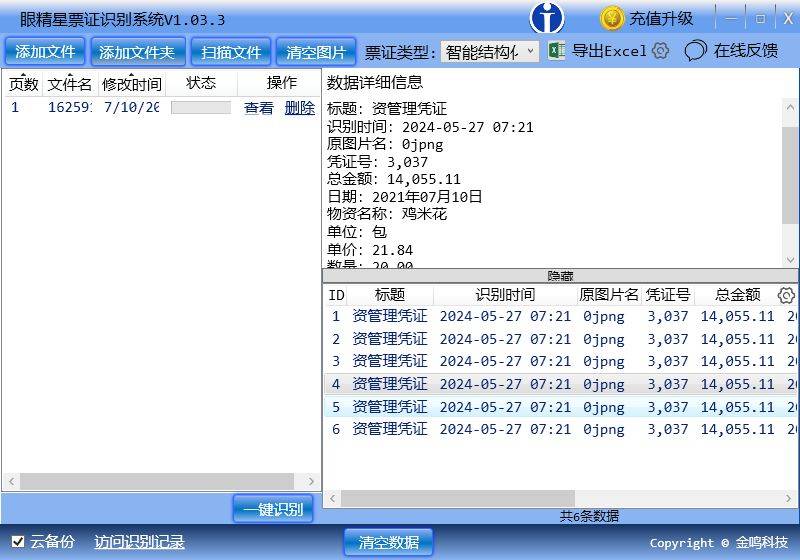
尽管OCR技术在文字识别和部分结构化数据处理方面取得了显著进展,但在以下场景中仍面临挑战:
在许多实际场景中,数据可能仅包含键值而没有明确的键名。例如:
在这种情况下,OCR难以通过规则或模板匹配生成结构化数据。
即使文档中存在键名和键值,如果它们的对应关系不明显(例如位置分散、格式不一致),OCR也难以准确匹配。例如:
OCR通常只能识别文字内容,而无法自动识别数据的类型(如日期、金额、地址等)。这需要额外的规则或模型来实现,增加了复杂性和成本。
为了解决上述困境,可以引入AI深度学习技术,通过数据的特征自动识别数据类型并生成结构化数据。以下是具体建议:
通过训练深度学习模型,识别数据的语义和类型。例如:
利用自然语言处理(NLP)技术,分析文本的上下文语义,推断键名与键值的对应关系。例如:
通过深度学习模型,自动生成适用于不同文档格式的模板,提高结构化数据的生成效率。例如:
在生成结构化数据后,通过规则引擎或AI模型对数据进行验证和修正,确保数据的准确性和一致性。
以金鸣识别为例,可以通过以下步骤实现基于AI的结构化数据生成:
OCR技术在文字识别方面已经达到了很高的水平,但在生成结构化数据方面仍面临诸多挑战,尤其是在缺乏键名或数据对应关系不明显的情况下。通过引入AI深度学习技术,可以自动识别数据类型、分析上下文语义,并生成高质量的结构化数据。未来,随着AI技术的进一步发展,OCR在结构化数据处理方面的能力将得到显著提升,为更多实际应用场景提供支持。
 在线客服咨询
在线客服咨询 Ctrl+D 收藏本站
Ctrl+D 收藏本站