

金鸣表格文字识别助手
人工智能表格识别准 | 批量合并更便捷
随着数字化时代的快速发展,文字识别技术已成为信息获取与处理的关键环节。其中,竖排文字识别因其在古籍、历史文档及特定领域的应用价值,日益受到研究者的关注。然而,竖排文字因其独特的排版方式和字符特点,给识别技术带来了诸多挑战。本文旨在探讨竖排文字识别中的核心问题,分析现有算法的表现,并提出相应的优化策略。

一、竖排文字识别的挑战
竖排文字识别面临的主要挑战包括字符分割、字符识别以及排版结构的还原。由于竖排文本中字符的垂直排列,传统的水平文本分割方法往往难以直接应用。此外,竖排文字中常出现的复杂字体和笔画结构,增加了字符识别的难度。最后,准确地还原竖排文本的排版结构,对于保持原文信息的完整性和可读性至关重要。
二、现有算法的分析
目前,卷积神经网络(CNN)和长短时记忆网络(LSTM)等深度学习算法在文字识别领域取得了显著成效。CNN通过其强大的特征提取能力,能够有效地处理图像中的局部特征;而LSTM则擅长处理序列数据,对于文本行或字符序列的识别具有天然优势。
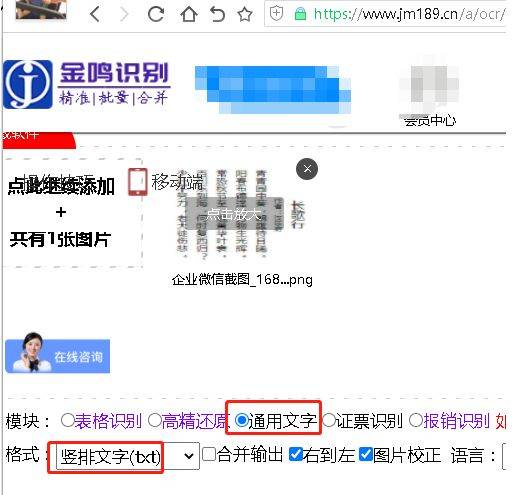
然而,在竖排文字识别中,这些算法也暴露出一定的不足。例如,CNN在处理竖排文字时,可能需要对输入图像进行预处理(如旋转),以适应其水平方向的特征提取机制;而LSTM在处理长序列时可能会遇到梯度消失或爆炸的问题,影响识别的准确性。
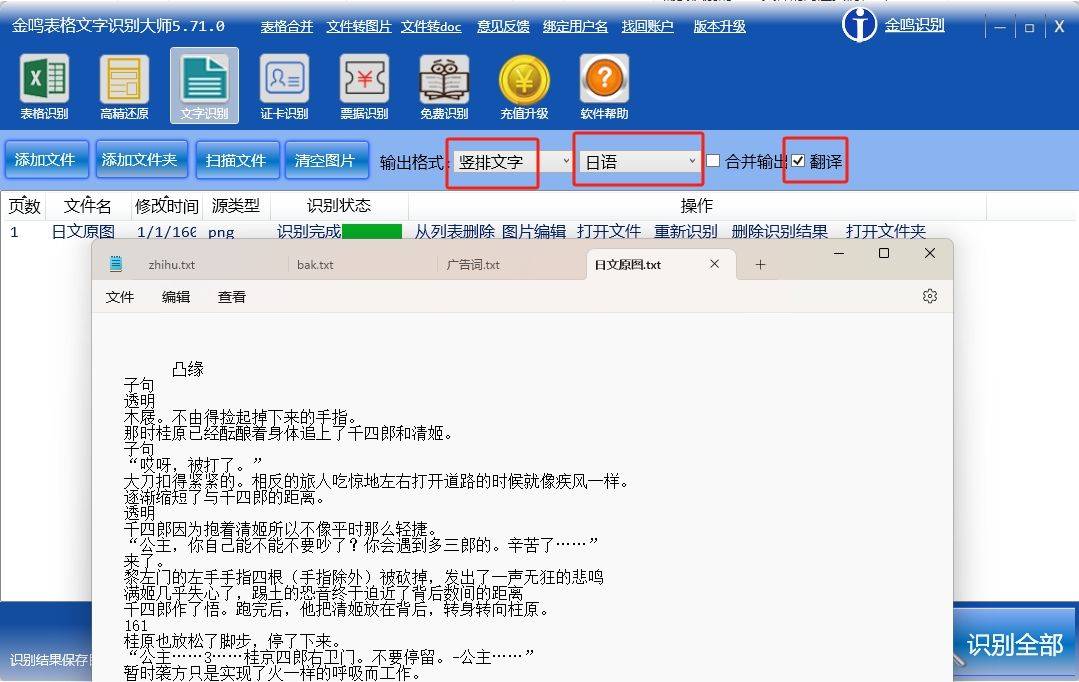
三、优化策略的探索
针对上述挑战和现有算法的不足,本文提出以下优化策略:
四、结论与展望
竖排文字识别作为文字识别领域的一个重要分支,其研究不仅具有理论价值,更具有广泛的应用前景。通过深入分析竖排文字的特点和识别难点,并针对性地提出优化策略,我们有望推动竖排文字识别技术的进一步发展,为古籍数字化、历史文档保护等领域提供更有力的技术支持。
 在线客服咨询
在线客服咨询 Ctrl+D 收藏本站
Ctrl+D 收藏本站