

金鸣表格文字识别助手
人工智能表格识别准 | 批量合并更便捷
随着深度学习技术的快速发展,OCR(光学字符识别)系统在横排文字识别任务中取得了显著的进展。然而,竖排文字识别由于其独特的排版方式和相对较少的数据集,仍然面临诸多挑战。为了提升竖排文字识别的准确性和鲁棒性,数据增强技术成为一种有效的解决方案。本文探讨了数据增强技术在竖排文字识别中的应用,并通过实验验证了不同增强方法对模型性能的影响。

数据增强是指通过对原始数据进行一系列变换,生成新的训练样本,从而扩展数据集并提升模型的泛化能力。在竖排文字识别中,常见的数据增强方法包括旋转、缩放、噪声注入、透视变换等。这些方法可以模拟真实场景中的多种变化,帮助模型更好地适应不同的输入条件。
竖排文字通常以垂直方向排列,但在实际场景中,文字可能会出现轻微的倾斜或旋转。通过对图像进行随机旋转(如±5°范围内),可以增强模型对旋转变化的鲁棒性。
文字的大小在不同场景中可能有所不同。通过对图像进行随机缩放(如0.9到1.1倍),可以使模型适应不同尺寸的文字。
在实际应用中,图像可能会受到噪声干扰(如高斯噪声、椒盐噪声等)。通过在图像中注入噪声,可以提高模型对噪声的容忍度。
竖排文字可能会因为拍摄角度或纸张弯曲而产生透视变形。通过对图像进行透视变换,可以模拟这种变形,增强模型对透视变化的适应能力。
光照条件的变化会影响文字的清晰度。通过随机调整图像的亮度和对比度,可以使模型在不同光照条件下表现更加稳定。
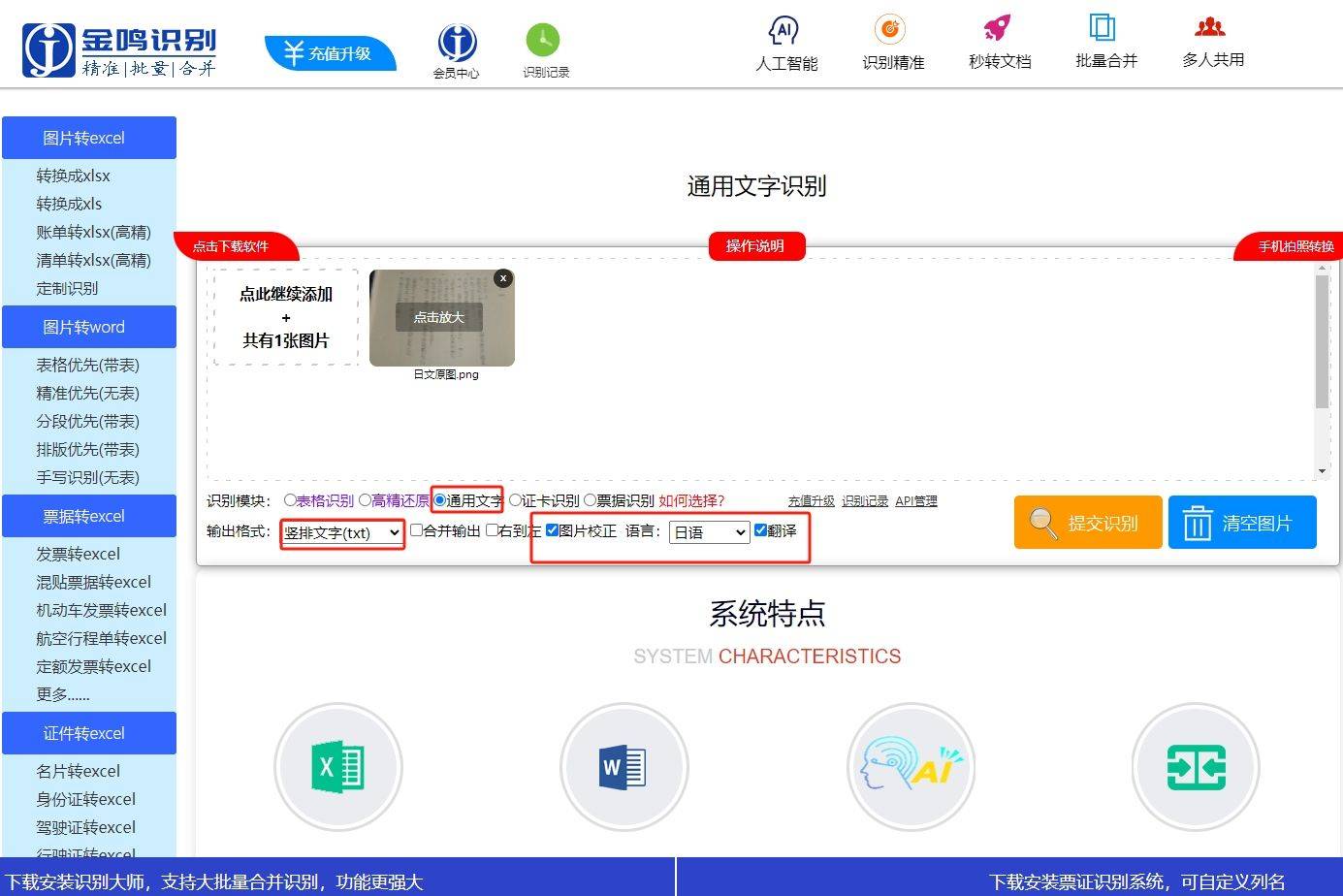
为了验证数据增强技术在竖排文字识别中的效果,我们设计了一系列实验。实验基于一个包含10,000张竖排文字图像的数据集,使用CRNN(卷积循环神经网络)作为基础模型。
我们通过字符准确率(Character Accuracy)和词准确率(Word Accuracy)来评估模型性能。实验结果如下表所示:
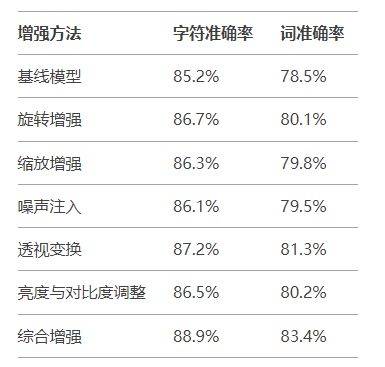
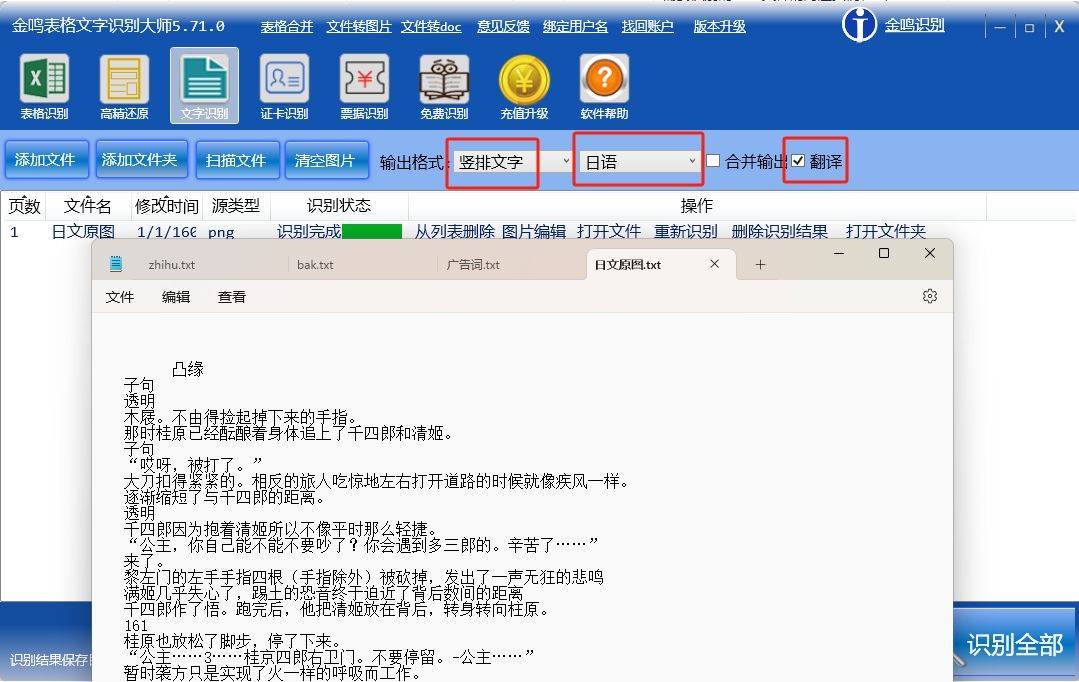
数据增强技术在竖排文字识别中具有重要的应用价值。通过旋转、缩放、噪声注入、透视变换和亮度与对比度调整等方法,可以有效扩展训练数据集,提升模型的鲁棒性和泛化能力。实验结果表明,综合使用多种增强方法能够显著提高模型的字符准确率和词准确率。未来,可以进一步探索其他增强方法(如字体变换、背景替换等)以及更复杂的模型架构,以进一步提升竖排文字识别的性能。
 在线客服咨询
在线客服咨询 Ctrl+D 收藏本站
Ctrl+D 收藏本站