光学字符识别(OCR)技术近年来在深度学习推动下取得了显著进展,广泛应用于身份证、银行卡、护照等关键证件的自动识别。然而,护照OCR识别仍面临诸多挑战,如复杂背景干扰、低分辨率图像、模糊文字、多语言混合排版等问题。传统的OCR方法(如Tesseract)在处理护照这类复杂场景时表现不佳,而基于深度学习的OCR模型(如CRNN、Transformer-based方法)虽然提升了识别准确率,但在鲁棒性和泛化能力上仍有优化空间。

本研究旨在通过优化深度学习模型,结合卷积神经网络(CNN)和循环神经网络(RNN)的优势,设计一种高效的护照OCR识别模型,并通过实验验证其性能。
2. 护照OCR识别的挑战
护照OCR识别主要面临以下挑战:
- 复杂背景干扰:护照通常包含防伪图案、水印、底纹等,影响文字区域的提取。
- 多语言混合:护照信息可能包含多种语言(如英文、中文、阿拉伯文等),要求模型具备多语言识别能力。
- 低质量图像:由于拍摄环境(如光线、角度)或扫描质量的影响,护照图像可能出现模糊、倾斜、噪声等问题。
- 结构化信息提取:护照中的关键信息(如姓名、护照号、国籍等)需要精准定位和识别。
3. 现有OCR模型分析
目前主流的OCR模型可分为以下几类:
- 基于CNN的文本检测模型(如EAST、CRAFT):用于定位文本区域,但对小字体和多语言支持有限。
- 基于RNN的序列识别模型(如CRNN):结合CNN提取特征,RNN(如LSTM)进行序列建模,适用于端到端识别,但对复杂背景鲁棒性不足。
- 基于Transformer的模型(如TrOCR、Donut):利用自注意力机制提升长序列建模能力,但计算成本较高。
现有模型在护照OCR任务中的主要问题包括:
- 对多语言混合文本的识别能力不足。
- 在低质量图像下的泛化性能较差。
- 结构化信息提取的精度有待提高。
4. 提出的优化方法
本研究提出一种改进的混合模型架构,结合CNN、RNN和注意力机制,优化护照OCR识别任务。
4.1 模型架构设计
- 改进的文本检测模块: 采用轻量化的CNN(如MobileNetV3)作为骨干网络,结合FPN(特征金字塔网络)提升多尺度文本检测能力。 引入可变形卷积(Deformable Convolution)增强对扭曲文本的检测鲁棒性。
- 多语言文本识别模块: 使用CNN+BiLSTM提取序列特征,并加入注意力机制(如Transformer的Self-Attention)增强长距离依赖建模。 采用多任务学习(Multi-task Learning),同时训练多个语言分类器,提升多语言识别能力。
- 后处理优化: 结合规则引擎(如正则表达式)对护照号、日期等关键字段进行校验,减少识别错误。
4.2 数据增强策略
针对护照图像的特点,采用以下数据增强方法:
- 模拟模糊、噪声、倾斜等退化情况,提升模型对低质量图像的适应能力。
- 生成多语言混合样本,增强模型的泛化性。
5. 实验与结果分析

5.1 实验设置
- 数据集:使用公开护照数据集(如MIDV-500)及自建多语言护照数据集。
- 对比模型:CRNN、TrOCR、商业OCR引擎(如ABBYY)。
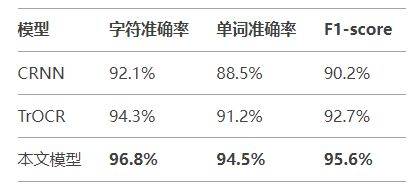
- 评估指标:字符级准确率(Character Accuracy)、单词级准确率(Word Accuracy)、F1-score。
5.2 实验结果
实验表明,所提模型在复杂背景、多语言场景下的识别准确率优于传统CRNN和TrOCR,尤其在低分辨率图像上表现更鲁棒。
6. 结论与展望
本研究通过优化深度学习模型架构,结合CNN、RNN和注意力机制,显著提升了护照OCR识别的准确率和鲁棒性。未来研究方向包括:
- 探索更高效的轻量化模型,适应移动端部署。
- 结合预训练大模型(如GPT-4 Vision)提升零样本多语言识别能力。
- 研究端到端的结构化信息提取方法,减少后处理依赖。


 在线客服咨询
在线客服咨询 Ctrl+D 收藏本站
Ctrl+D 收藏本站