

金鸣表格文字识别助手
人工智能表格识别准 | 批量合并更便捷
在将图片中的文字识别转换为word文档时,我们很多时候时会遇到识别内容的一个自然段还没结束就换行的问题,这些就是我们常说的多余换行的问题。为什么会产生这个问题呢?主要是由于ocr返回的识别结果是按图片上的文字换行而换行,而不是以自然段为换行依据。
这会产生什么样的危害呢?一是word中会出现很多多余的回车符,看起来很是障眼,特别是对有“洁癖”的人来说,心里更不是滋味,怎么办呢?
笔者推荐的方法是使用金鸣表格文字识别大师来解决。具体操作方法如下:
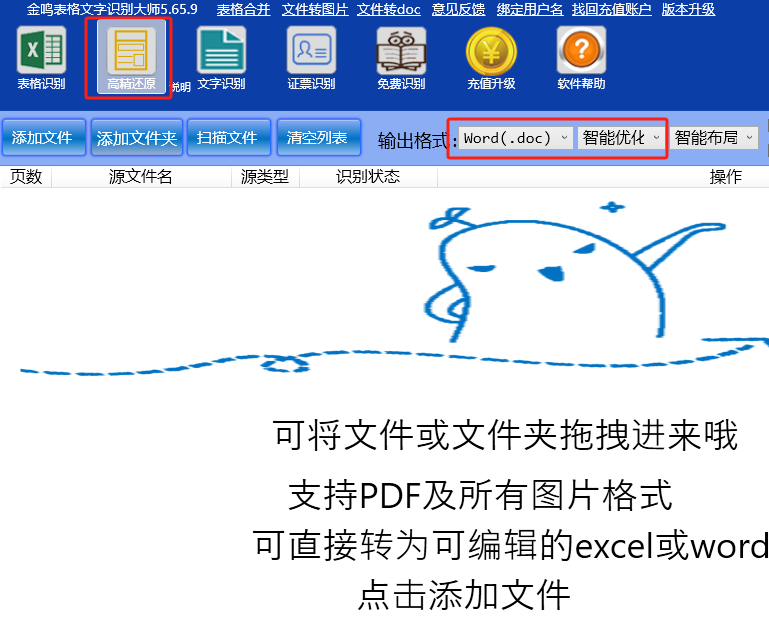
一、使用高精还原的“智能优化”输出。选择这种输出方式,程序会调用ai智能分段功能,将自动识别自然段,只有满足一个自然段的条件下才会换行。这种输出方式最适合文字较多的图片,如文章、图书、公文等。
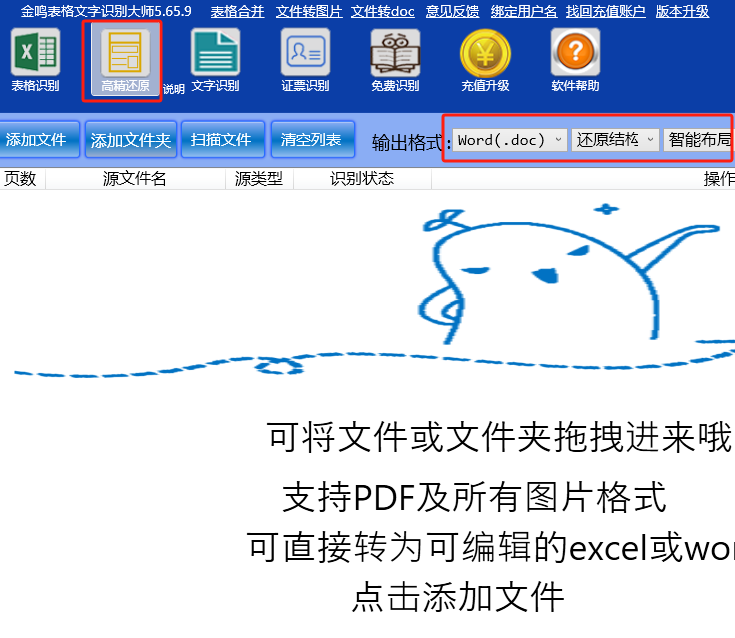
二、使用高精还原的“还原结构”。还原结构即还原排版,使用这种方式输出,程序在ocr识别后会根据图片上的文字坐标,还原原有的文字排版,从而避免出现多余的换行。采用这种方式的好处是能还原排版,缺点是图片需要保持整洁和端正,如果图片上的文字排列歪了的话,出来的word排版也会歪,因此,这种输出方式最适合截图识别,以及用传统扫描仪成像的图片识别。
在金鸣表格文字识别移动端,“分段优先”对应“智能优化”,而“排版优先”则对应“还原结构”,它们转出来的效果跟电脑软件是一样的。
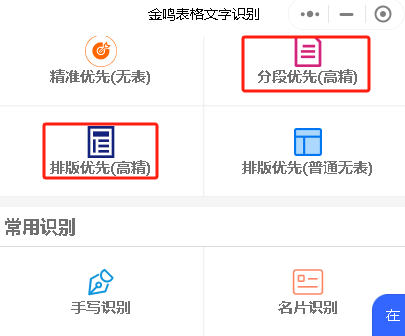
另外一种处理方法就是ocr识别后手工处理。在ocr识别后,可以使用文本编辑软件(如notepad++、sublime text等)对识别结果进行处理。例如,可以使用“查找和替换”功能来删除多余的换行符;或者使用“段落格式化”功能来重新排版文本。这种方法比较麻烦,会增加较多的工作量。
总之,为了避免在将图片转换为word文档时出现多余的换行问题,我们可以选择专业的ocr软件(如金鸣表格文字识别大师),以及进行识别后处理手工处理等方法。这些方法能够有效地提高ocr识别的准确性,并避免出现不必要的换行问题。
 在线客服咨询
在线客服咨询 Ctrl+D 收藏本站
Ctrl+D 收藏本站