

金鸣表格文字识别助手
人工智能表格识别准 | 批量合并更便捷
在信息爆炸的时代,图片和PDF文件常常成为我们日常工作中不可避免的数据来源。然而,将这些非结构化的数据转化为可操作的结构化信息是一项挑战,特别是图片生成的PDF,要用到光学字符识别(OCR)技术时。本文将探讨如何通过OCR智能结构化识别技术,将从PDF文件中提取的数据进行有效汇总。
眼精星OCR智能结构化识别简介
OCR智能结构化识别是眼精星票证识别系统的其中一个模块,其原理是利用OCR技术将扫描或拍摄的图像中的文本信息转化为计算机可以处理的结构化格式。与传统OCR技术不同,这种方法不仅识别文本,还能够智能地解析出数据中的关键信息,如日期、金额、姓名等,并将其组织成结构化的数据。这种技术使得我们可以更高效地处理和分析大量从图片或PDF中提取的信息。
从PDF到Excel的挑战
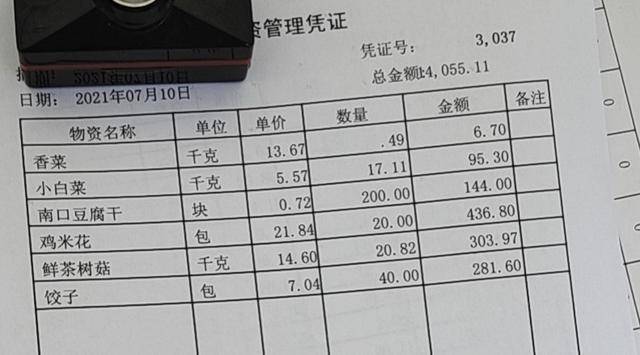
在实际应用中,我们常常需要将来自客户的订单PDF文件转换为Excel格式,以便进行进一步的数据处理和汇总。然而,采用通用的表格文字识别的OCR转换的结果往往由于格式不稳定而存在问题,例如行列的变动或数据的错位。这种情况使得数据汇总的过程变得繁琐且耗时,尤其是当需要搜索特定关键字(如“单价”)并提取相关数据时。
实现数据汇总的步骤
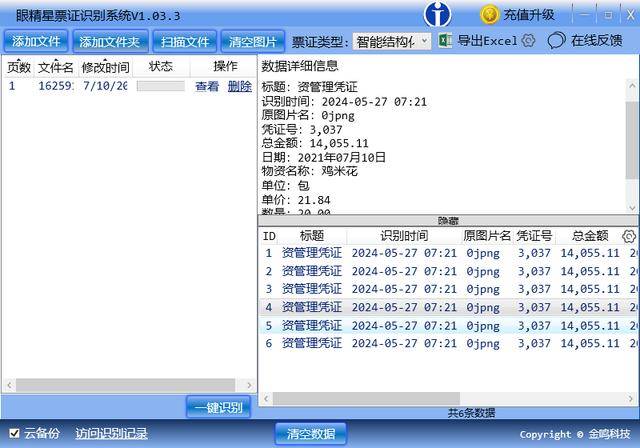
1. OCR转换:首先,下载安装眼精星票证识别系统,然后在下拉菜单处选择“智能结构化”,再将待识别的图片或PDF添加进去,点击一键识别,这样就可瞬间将PDF或图片上的数据转化为结构化数据了。
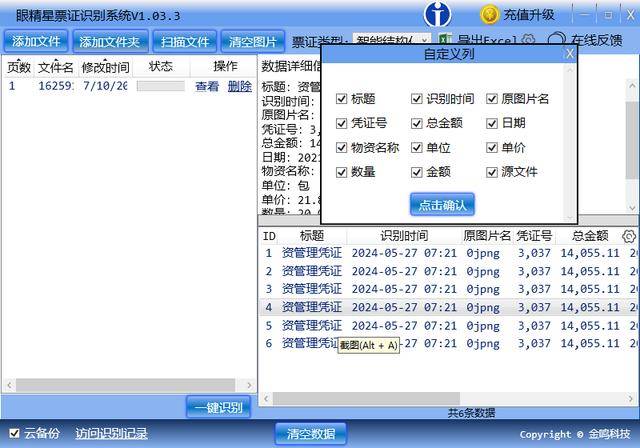
2. 选择要显示或导出的列名:点击“导出excel”旁边的齿轮图标,调出自定义列名窗口,去掉不需要显示和导出的列名,然后点击“确定”。
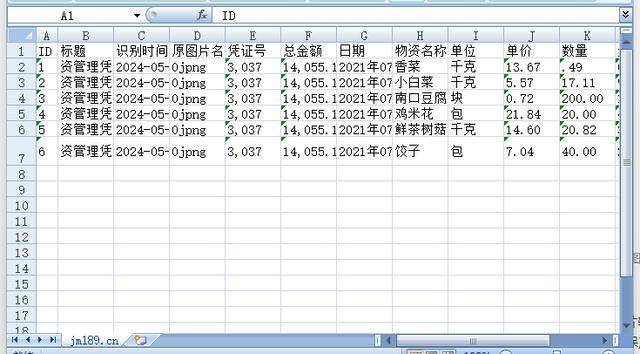
3. 导出excel:点击“导出excel”,即可将所有识别好的数据导为excel。
结论
眼精星票证识别系统的智能结构化识别技术为从PDF到Excel的数据处理提供了有效的解决方案。通过结构化识别和自动化数据处理,能够显著提高数据汇总的效率和准确性。在面对有大量数据的图片或PDF时,这种方法尤其有效,能够帮助减轻工作负担,提升整体工作效率。
 在线客服咨询
在线客服咨询 Ctrl+D 收藏本站
Ctrl+D 收藏本站